How Enterprise Migrations to Discourse Actually Work


If you’re responsible for an enterprise community, you’ve probably had a version of this conversation already:
“Our current platform is creaking. We need better search, better moderation tools, better integrations. But if we move and something goes wrong, it’s on us.”
Most engineering leaders aren’t afraid of new technology; they’re afraid of migrations that behave like black boxes. Someone says “we’ll take care of it,” a few weeks pass, and you’re asked to flick DNS and hope nothing critical broke.
That’s not how we run enterprise migrations to Discourse.
Behind the scenes, these projects look much more like any other serious engineering effort: clear phases, dedicated environments, data mapping decisions you help shape, and explicit risk controls. This post is about opening that up so you can see how an enterprise migration actually works, not just the marketing version.
What “Enterprise Migration” Actually Means
In this series we’re focused specifically on Enterprise migrations - the projects where:
- Data volume is large, or the source platform is complex.
- There are non‑trivial permission models, tags, product areas, or regional communities to preserve.
- Multiple teams (engineering, security, community, product) are involved in decisions.
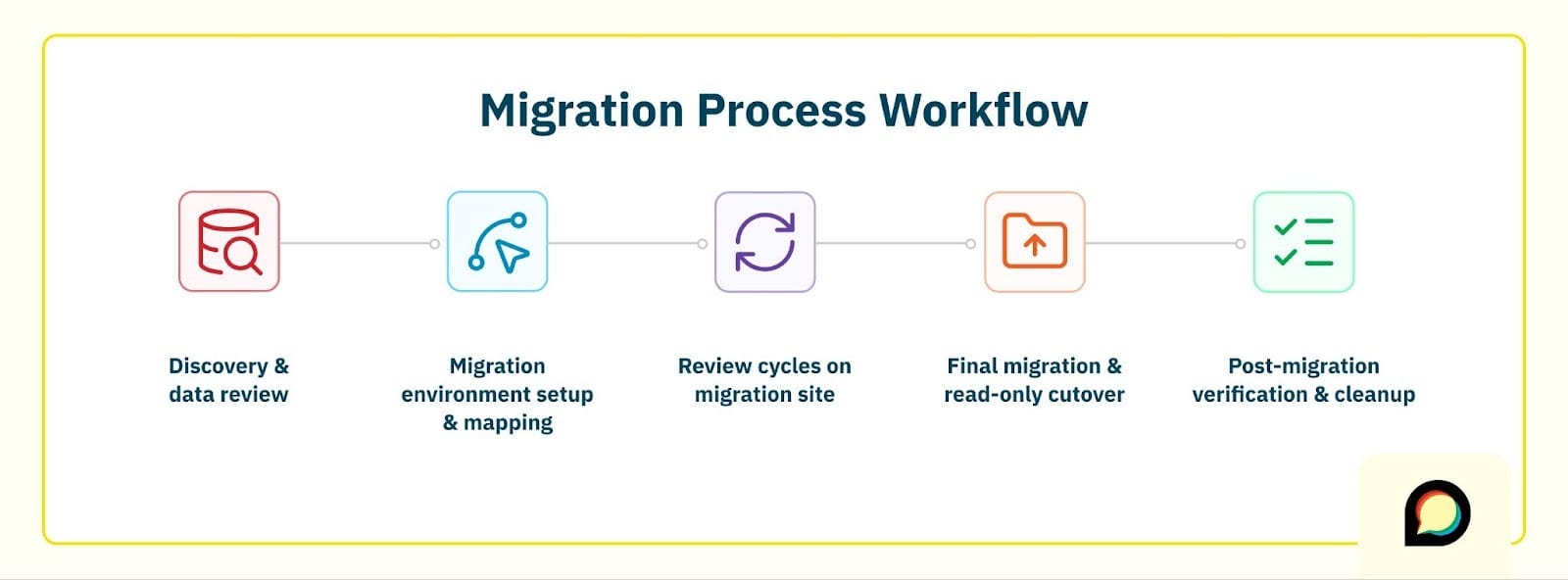
The Enterprise flow still follows a familiar lifecycle:
- Discovery & data review
- Migration environment setup & data mapping design
- Review cycles on a dedicated migration site
- Final migration & read‑only cutover
- Post‑migration verification & cleanup
The rest of this post walks through those phases from your perspective, using a real (anonymized) Khoros → Discourse migration as the running example.
Environment Topology
In Enterprise projects we typically work with three kinds of sites:
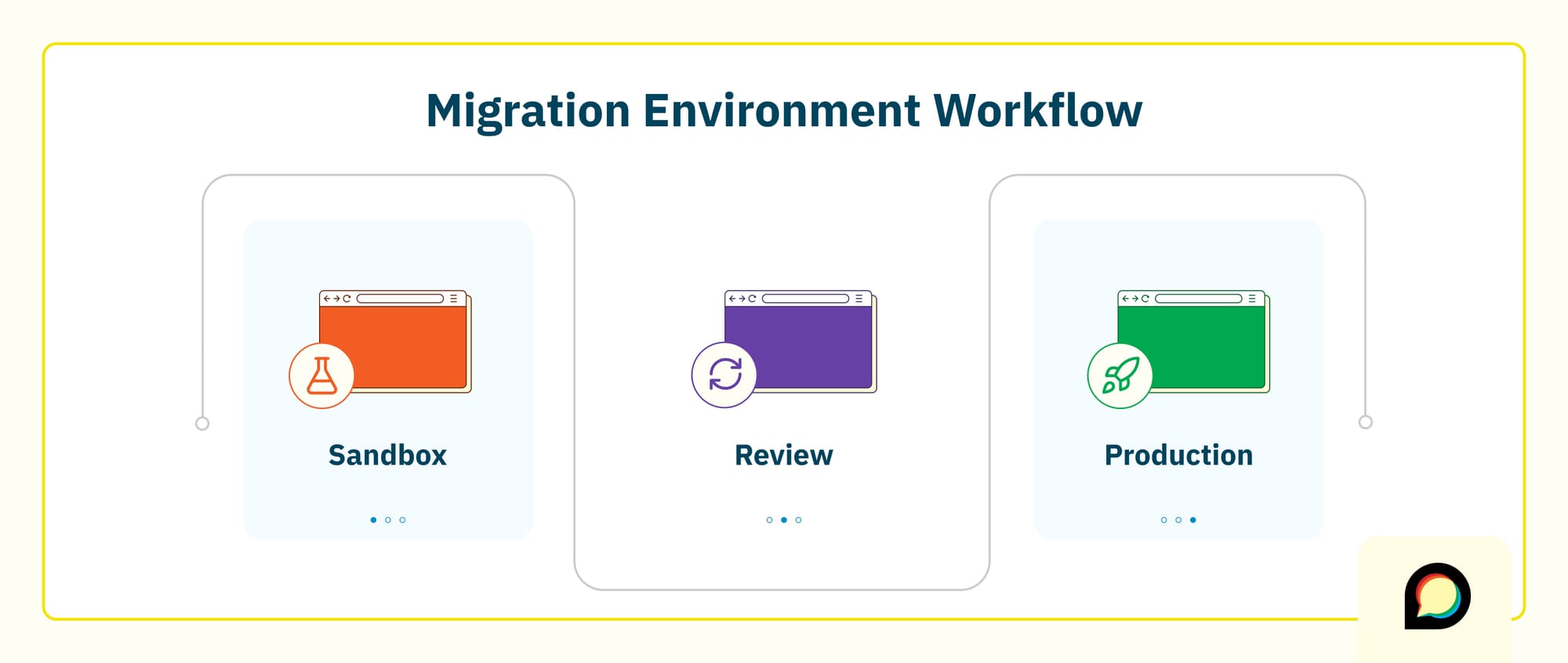
- A sandbox / configuration site where your team experiments with themes, settings, plugins, and SSO. This stays empty of imported content and lets you iterate on how the future site should feel.
- A migration / review site that contains imported data. We reset this site as we refine the import, so you’re always testing against a clean, consistent view of how content will look on Discourse.
- A production site where your community ultimately lands. At launch, this site ends up with both your final configuration and the final migrated content.
Conceptually, it’s a controlled assembly line:
Source platform → migration environment → reviewed migration backup → production site
Each step has its own risk controls, checklists, and “go / no‑go” decision points before we move forward.
Phase 1: Discovery & Data Review
Before we write any migration code, we start with a data review of a sample (or full) export from your current platform. Think of this as the architectural assessment: what are we actually moving, and what will it take to move it safely?
In practice, that means pulling your export into a database, running targeted queries, and answering questions like:
- Do we have reliable identifiers for users, topics, posts, categories, tags, and private messages?
- Are emails present and usable as the backbone of identity on Discourse?
- How many posts, uploads, and private messages are we dealing with - and what does that imply for migration time?
- Are there custom fields, badges, or ranking systems that matter enough to migrate?
We then translate those findings into a scoped plan you can react to:
- What we will migrate (for example, all public topics and replies since launch, all PMs over the last N years, active users plus historical staff accounts).
- What we won’t migrate (for example, deprecated features, auto‑generated notification content, or clearly broken legacy objects).
- Any transformation needs we’ve already spotted (for example, HTML quirks that will need cleanup on the way to Markdown).
On your side, this is where your engineers and community team are most useful when they:
- Explain how your current categories, groups, and roles work.
- Flag “sleeper requirements” like regulatory tags, internal‑only areas, or archived programs that still matter for compliance.
- Help us understand which parts of the historical record are sacred, and which can be trimmed.
The output is a migration findings summary you can share internally: what’s possible, what’s in scope, and where the complexity lives.
Phase 2: Migration Environment & Data Mapping Design
Once scope is agreed and contracts are in place, we create a dedicated migration environment and start designing the data mapping with you, not in isolation.
Migration Environment (Conceptual View)
The migration environment is a safe place to experiment with imports without touching your production community. We load your export, run migration scripts against it, and write into the migration / review site you’ll eventually use for QA.
The important properties from your perspective are:
- It’s isolated from production.
- It’s repeatable - we can wipe and re‑import as we refine the mapping.
- It’s time‑boxed - when the project is complete, we tear it down and remove temporary data.
Designing the Data Mapping Together
In an Enterprise Khoros → Discourse migration we recently completed for a large enterprise customer, most of the real work in this phase was about making good mapping decisions together:
- Categories and information architecture
Their legacy platform had a deep category tree with product lines, programs, and archived areas. For that project we started with a shared mapping document that listed every legacy category, mapped each one to a Discourse category (or tag), and marked which sections should be archived into read‑only areas. On other projects, the mapping can be more automated - pulling structures straight from the export and applying rules based on slugs, IDs, or metadata - when customers don’t need that level of manual control. Either way, the goal is that by the time data lands on Discourse, the category structure reflects how you want people to navigate, not how the old system happened to grow. For teams new to Discourse, it often helps to review how categories and their settings work before locking in the mapping.
- Tags and topic classification
Tags in the old system were used inconsistently - sometimes as product labels, sometimes as campaign markers, sometimes as noise. Together we defined a set of tag groups (for example, products, regions, program types) and built an allow‑list so that only tags that mattered were migrated, and only into the right parts of the new structure. The end result was that topics that belonged together actually shared the same, clean set of tags, instead of being scattered across a mix of similar‑sounding labels. The public admin guide to tags and structured tagging with tag groups are good references for this part of the design.
- Groups, roles, and permissions
Legacy groups like “Product Champions,” “External Experts,” and various internal teams needed to become Discourse groups with clear meanings and powers. We co‑designed a mapping that:
- Preserved who belonged to which group.
- Ensured sensitive areas (like staff‑only and security spaces) stayed locked down.
- Avoided giving category moderators more power than compliance teams were comfortable with.
- Trust levels and program status
Khoros rankings carried social meaning (e.g., “Platinum”, “Gold”, “Community Leader”). For this migration, some of those became Discourse trust levels, while others became badges and group memberships. The goal wasn’t a 1:1 copy of the old system; it was to preserve status signals in a way that fit how Discourse works - and then use that as a foundation to introduce stronger, modern moderation tools, including Discourse’s AI‑assisted spam detection and review flows, so the program could scale without relying only on manual review.
None of these mapping decisions came from code alone. They came from:
- What we could see in the export.
- What your teams told us about how the community actually uses those structures.
- What you want the future experience to look like.
The converter then becomes the implementation of those decisions. But the design phase is collaborative by necessity.
Phase 3: Review Cycles on the Migration Site
Once we have an initial mapping implemented, we import it into the migration / review site and ask everyone to stop looking at spreadsheets and start looking at real topics.
The first pass rarely feels perfect. That’s by design.
In the Khoros migration, the first migration site revealed that:
- Some archive categories were still too visible for day‑to‑day users.
- A few high‑value tags were missing because they hadn’t made it into the initial allow‑list.
- Category moderators had more power over deletion than the customer’s legal team was comfortable with.
Those findings didn’t mean the migration was failing; they were exactly the feedback we needed. The customer logged issues against the migration site, we updated the mappings and configuration, wiped the site, and ran a second import. Each round moved us closer to a Discourse structure that matched how they wanted to run the community going forward, not just how the old system happened to evolve.
As a practical matter, this phase works best when:
- Your team has a clear checklist of what to test (we provide one, the pre‑launch checklist for Discourse migrations).
- There’s a single place to capture feedback, with someone on your side triaging what’s critical for launch versus what can wait.
- Everyone understands that we’ll do multiple full re‑imports; the goal is not to “patch the first import” but to improve the mapping and rerun it.
Phase 4: Final Migration & Cutover
Once everyone is satisfied with the migration site, we plan the final cutover. This is the moment where your legacy platform becomes read‑only and Discourse takes over as the “source of truth” for new content.
There are more moving parts here, but at a high level the flow looks like this:
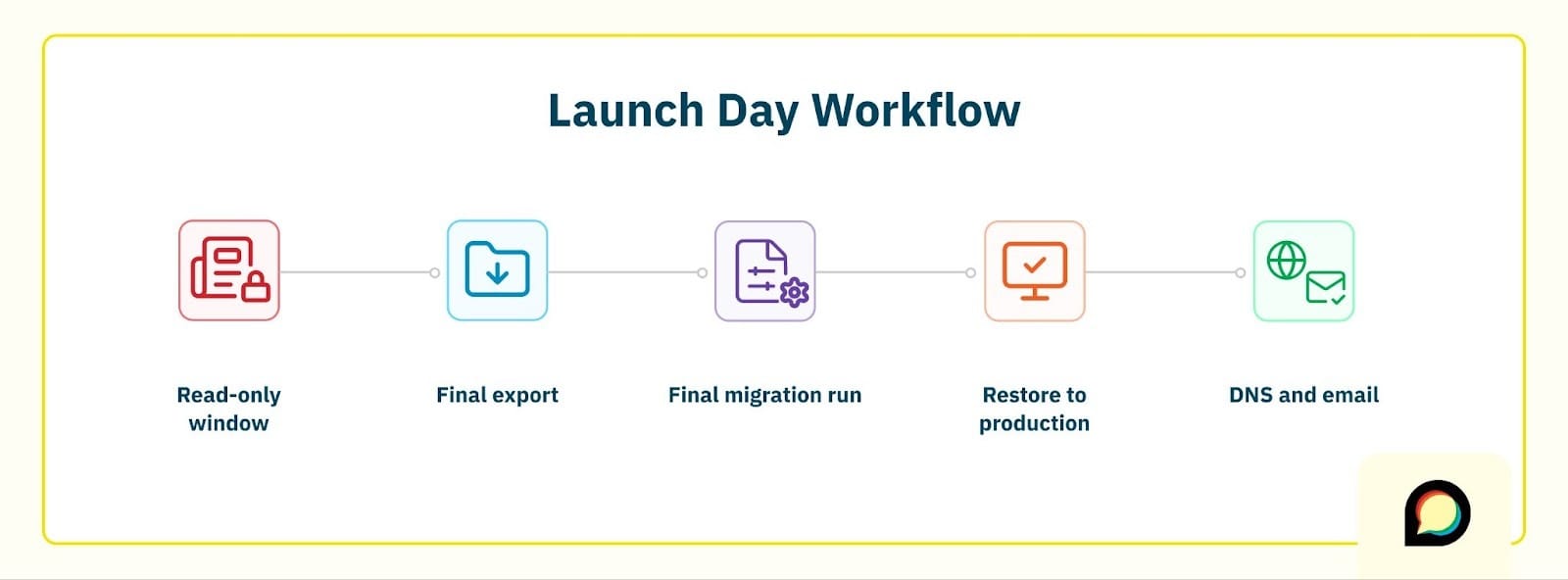
- Read‑only window
At an agreed time, you put the old platform into read‑only mode so no new posts or replies are created there.
- Final export
You generate a final backup/export and send it over - this is the snapshot we’ll use for launch.
- Final migration run
We combine:
- Your finalized Discourse configuration (from the sandbox work).
- The latest data from the final export.
The result is a Discourse backup that contains both how the site should look and what it should contain.
- Restore to production
We restore that backup to your production Discourse site, run through a focused smoke test, and confirm that the critical checks still pass.
- DNS and email
Finally, you update DNS to point your final domain name at the Discourse site, email notifications are re‑enabled, and any temporary restrictions used during migration are adjusted.
The details inside each step matter to us, but the key decisions on your side are still human:
- When can your community tolerate a read‑only window, and how long can it reasonably last?
- Who needs to be on point from engineering, community, and support during that window?
- How are you going to explain the transition to members so they’re not surprised when the old site stops accepting new content and the new one appears?
Phase 5: Post-Migration Verification & Cleanup
Even with thorough QA, some issues only surface when the full community is back on the site. That’s why post‑migration verification is a formal phase, not an afterthought.
Right after launch, the focus is narrow and practical:
- Are the numbers roughly where we expect them to be - users, topics, posts, uploads?
- Can the right people log in with the right permissions?
- Do legacy links (especially the ones you care about most) land in the right place on Discourse?
In the Khoros migration, this is where we discovered things like:
- A small number of usernames that needed Unicode support turned on in order to edit them.
- A handful of category redirects that still pointed at an early staging structure.
- A set of “tips & tricks” topics that had been intentionally closed during migration and then needed to be reopened in bulk after launch when the community decided they wanted fresh replies.
None of these were show‑stoppers, but all of them would have been painful if we hadn’t planned for a period of heightened attention. Each fix was first tested against the migration site, then applied to production: configuration changes, redirect updates, and (when needed) small follow‑up scripts that touched only the Discourse side, never the legacy platform.
Once we’re confident things have settled:
- Temporary migration sites are decommissioned.
- Migration‑specific backups and exports are removed according to policy.
- The project is documented internally so that the next Enterprise migration can benefit from what we learned.
Roles, Responsibilities, and Risk Controls
A key difference between “a risky one‑off migration” and “a repeatable process” is clarity on who does what, when, and with what safeguards.
On our side, we own the migration environment, the import logic, the QA of Discourse‑specific behavior, and the operational checklist that keeps things predictable. On your side, you own your data exports, the definition of scope, the decisions about information architecture and permissions, and the communication with your members.
Across the phases, the risk controls are simple but important:
- We don’t start implementation until we’ve verified that the right data is present and agreed what’s in scope.
- All early import work happens away from your production community.
- We plan for multiple full re‑imports during review, so we can bake feedback into the mapping instead of patching around it.
- We treat cutover as an operation with backups at each step, not a single irreversible jump.
- We explicitly plan for a period of heightened monitoring and post‑migration fixes.
How to Evaluate This as an Engineering Leader
When you look at this process, treat it like any other critical platform change. Ask how phases, environments, and rollback options work in concrete terms. Make sure your engineers and community leaders have meaningful roles in the review cycles. And look for signs of repeatability - checklists, tools, and patterns - rather than one‑time heroics.
Ultimately, a reliable process with many checkpoints is what makes an enterprise migration manageable instead of risky.
If you’re planning a move to Discourse and want to understand what this process looks like for your team, we’d be happy to walk you through it.
Comments